スパコンポエムAdC2020 Day13 SX-Aurora TSUBASAについて酒を飲みながら書いたポエム
はじめに
この記事はスパコンポエムAdC202013日目の記事です.
山田先輩に誘われたはいいものの,私はQiitaのテーマカラーの緑が嫌いなので自分のブログに勝手に書きます.
コメントしたいけどQiitaじゃないからコメントできない!!!と思った人はTwitterにでも書いてください.頑張って発掘します.
今回の記事はSX-Aurora TSUBASA (SXAT)です. SXATはスパコンじゃないだろって? 何いってんだここにスパコンだって書いてある.
まぁ冗談はさておき東北大のAOBA-AやNIFSの雷神に搭載なので問題ないでしょう. あと次期地球シミュレータにも搭載らしいですね.
この記事ではSXATの演算器構成と,さすがNECとも呼べる自動ベクトル化を最大に活かしたプログラミングモデルについて紹介します. 最後に簡単にSTREAM代わりの内積プログラムの性能について紹介していこうと思います.
いくつかの注意
- 僕は1ノードまでしか使ったことないので1ノードに限定して書きます
- 使ってるモデルがType 10-Bというやつなので,東北大や雷神とは動作周波数などが若干違います
- 明らかに [1] [2]関係者ですが公開情報に基づいて書いています.ただしチャンピオンデータを使った神輿担ぎはしてません
- この記事は個人として書いているので所属とは関係ない
以上についてご了承ください.
SX-Aurora TSUBASAとは
SX-Aurora TSUBASAはシステム全体の名前で,
- ホストとなるマシンをVH (Vector Host),
- PCIe Gen3接続のアクセラレータボードをVE (Vector Engine)
と呼びます.
↑これ大事
で,VEですが,
これがVEだ!!!!!!!!

\バーン/
~おわり~
制作・著作
━━━━━━
ⒽⓅⒸ
↑これは後輩の@recorderさんが作ってくれました.
本題に戻りますが赤いボードだそうです.NECって赤でしたっけ?
半導体に詳しい山田さんはこれを見るだけで演算器構成が透けて見えると思いますが, 僕のような若輩にはまだまだ無理なので,ここからちゃんと調べた結果を紹介します.
ちなみに大体の情報はここにあります.
現状ではVHはIntel CPUのモデルだけのようですが,次期地球シミュレータではEPYCになるらしいので,今後PCIeのカード販売が進むにつれて色々なモデルがでるんじゃないでしょうか.
VEの性能
特徴的なのはVEで,これがいわゆるベクトル機になっています.
Type-10Bと呼ばれるVEの諸元を以下の表に示します.
| Model name | Type 10B, 1.4 GHz, 8 core |
|---|---|
| Peak | 2.15 TFlops (DP) / 4.3 TFLOPS (SP) |
| Memory | HBM2 48 GB (B/W 1,228 GB/s) |
| LLC | 16 MB |
DPeak 2.15 TFlopsとそこそこ高いピーク性能とHBM2が48GB載っているのが特徴です. 48GBというのは今度出るNVIDIA A100 (80GB)を除けば恐らく最大容量です. 1枚のメモリが大きいというのは機械学習や数値シミュレーションではMPIをやらなくて良い分有利なので,個人的には好きです.
先程の記事によるとVEのカード1枚の価格は114万4000円からとのことで,対抗他社製品と比べてもそんなに高くないんじゃないでしょうか.
では,2.15TFLOPSというピーク性能の内訳について,演算器構成を見ていきます.
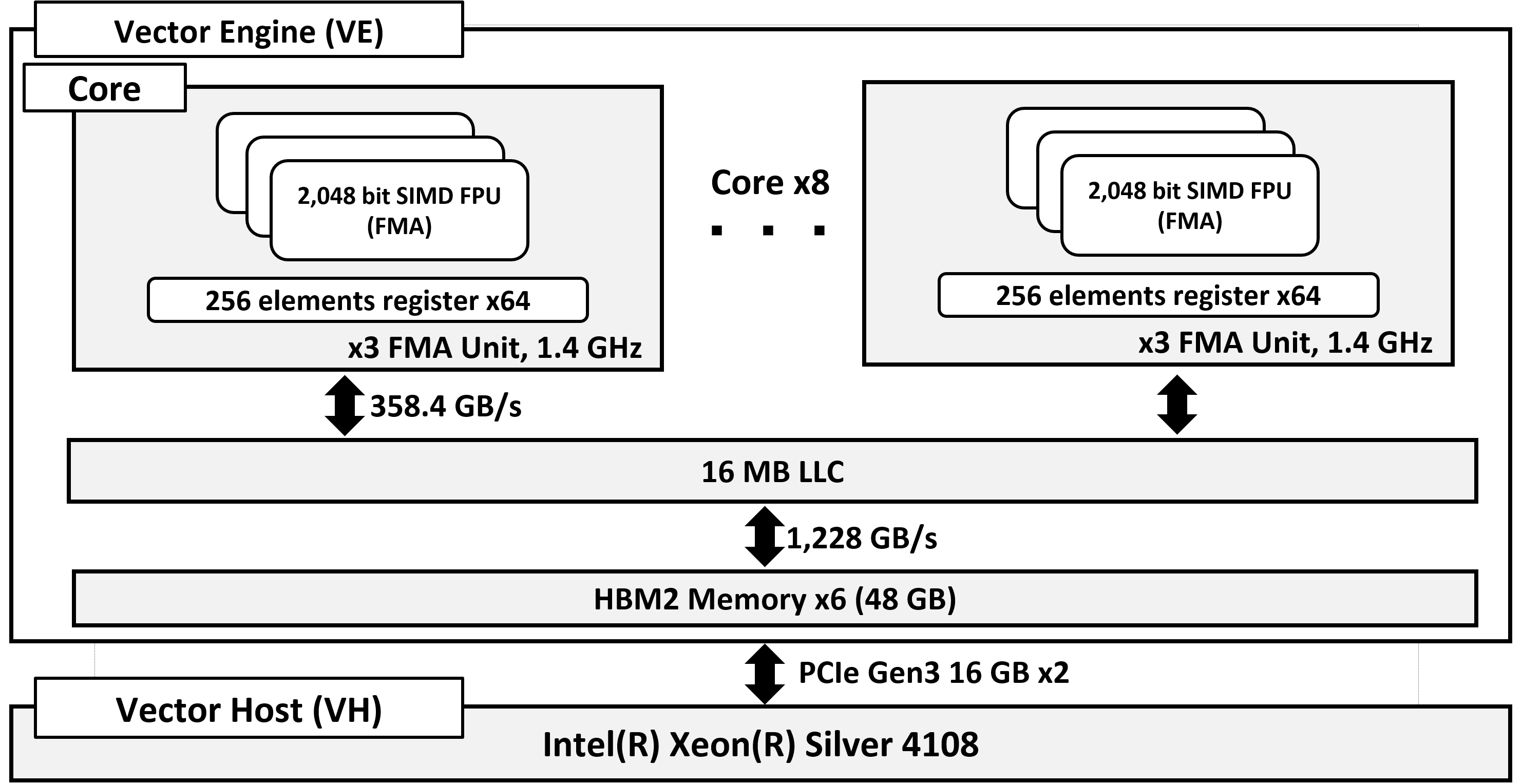 SX-Aurora TSUBASAの構成 (Type-10B) (出典:菱沼 利彰, 井原 遊, 高村 守幸, 平野 哲, 萩原 孝, 岩田 直樹, 奥田 洋司, SX-Aurora TSUBASAにおける有限要素解析のための共役勾配法の性能評価, 情報処理学会研究報告, Vol. 2020-HPC-175 (SWoPP2020), No. 18, pp. 1–10, 2020.07.)
SX-Aurora TSUBASAの構成 (Type-10B) (出典:菱沼 利彰, 井原 遊, 高村 守幸, 平野 哲, 萩原 孝, 岩田 直樹, 奥田 洋司, SX-Aurora TSUBASAにおける有限要素解析のための共役勾配法の性能評価, 情報処理学会研究報告, Vol. 2020-HPC-175 (SWoPP2020), No. 18, pp. 1–10, 2020.07.)
この図では,下の小さい箱がVH,上の大きい箱がVEとして書いています.
VEは8つのコアを搭載していて,各コアには型に依らず最大256要素を格納するベクトルレジスタが64本と倍精度32要素に対して同時にFMA (Fused Multiply and Add)演算を実行できるFPUが3器搭載されています.
ベクトルレジスタに格納,演算できるデータ数は可変で,データ数が256要素に満たない場合でもデータを256の倍数に揃えずにベクトル計算を実行できます.
ベクトルレジスタ内にデータが256要素格納されているとき,FPUはベクトルレジスタのデータに対して256 / 32 = 8 サイクルかけて計算を行う形で処理されます.
そのためVEにおいて倍精度演算を行う場合のピーク性能は次のように計算できます.
1.4 [GHz] × 8 [core] × 32 (要素) × 6 (FMA × 3基) = 2.15 [TFLOPS]
周波数についてはいくつかのモデルがあるそうです.お手元のVEが何クロックで動いているかは手を触れるだけで水晶発振器の振動が読み取れると噂の山田さんに聞いてください.
プログラマとして考えなければいけないのは,
- 8つあるコアのためのスレッド並列
- 倍精度32要素を同時に処理するSIMDのデータ並列
の2つになってきます.
続いて帯域関係の話に移ると,
- メモリ帯域は1,228 GB/sで,Byte / Flop (B/F)は1,228 / 2,150 = 0.57
- コア共有のLLC (Last Level Cache)のサイズは16 MBで,各コアとLLC間の帯域は358.4 GB/s
ここがちょっと面倒で,VEは1コアあたりのLLCとの帯域が358.4 GB/sなので,メモリバンド幅である1,228 GB/sを引きだすためには1,228 / 358.4 = 3.4 コア相当の帯域が必要で, スレッド並列は必須になってきます.
SX-Aurora TSUBASAのプログラミングモデル
SXATはこれまでのアクセラレータボードとは違う,特徴的とも言えるプログラミング方式を採用しています.
一般的にアクセラレータボードのプログラミング方式は
- Xeon PhiやCell B.E.のようにアクセラレータボード上で動作するOSにログインしてプログラムを実行する (データ転送はscpなど)
- GPUのように関数なりpragmaなりでデータ転送を記述してデバイス上で動作するプロセスをホストから明示的に上げる
の2つかと思います.
一方,SXATではどちらとも違う, VHからVE向けにコンパイルされたバイナリを実行すると自動的にVEにプロセスが上がる という方式をとっています.
VH上で動作するVEOSとよばれるVE上で動作するプロセスを制御するソフトウェアが提供されています. VEOSはVEからはOSのように見えていて,VEにLinuxシステムコールなどを提供します.
VEOS側は必要に応じてVE側のプロセスに対してデータ制御などを行ってくれるため, I/Oやシステムコールなどの処理は自動的にVEOSを通じてVHと協調して行われます.
そのため,NECコンパイラを用いてVE向けにコンパイルしたプログラムをVHから実行するだけで, VEOSによってプロセスがVE上に展開されて処理が行われ,ユーザがプログラムを変更したり,VEとVH間の転送を意識する必要がありません.
また,SXATではVHとVEを連携させて計算するハイブリッド計算用のAVEOというAPIも提供されており, VHのプログラムはOpenCLっぽい記述でデータオフロードを書いてgccでコンパイル,NECコンパイラで作ったバイナリを呼ぶような形になってます.
コンパイラとしてはC/C++/Fortranのコンパイラが動作するようになっています. 今のところ何でもコンパイルできていて,トラブルは特にぶつかってないです.
高速化の方法は,スレッド並列にはOpenMPやpthread, プロセス並列にはMPIが使用できます. これらの環境変数などの挙動も普通の環境と同じです.
コア内のベクトル化にはコンパイラによる自動ベクトル化,およびコンパイラへの指示句を利用できます.
コンパイラが賢いらしく指示句を使わなくても間接参照が必要な疎行列ベクトル積を自動ベクトル化してくれました. 明示的に特殊な命令を使いたい場合じゃなければ使わなくていいんじゃないでしょうか.
実際どうなの
はじめからスレッド並列されてるプログラムなら特に何もしないで動いて帯域を引いてくれます. たとえばSTREAMとかReference BLASなどは勝手に自動化してくれ,帯域を引く程度まで自動ベクトル化してくれました.
Reference BLAS程度の大きさのソフトウェアがコンパイラをgccからnccに変えるだけで10倍くらい速くなったのは良い感じかと思います.
また,48 GBと大きいメモリが使えるだけでなく,Xeon PhiやCell B.E.のようにログインして使うわけではないので, デバイス側のOSに入力ファイルなどが溜まって圧迫してこないことも良い点かと思いました.
STREAMみたいなソフトであれば実行と同時にプロセスがVEに上がって,VEの中でメモリを確保して舐めるだけなので, 起動みたいな時間が違って目立つとかは感じず,ホスト実行と同じような感覚で実行し,プログラム全体の時間が純粋に速くなっているように感じました.
また,コンパイラは周辺ソフトウェアはyumで管理されていて,NECリポジトリを登録して色々落としてきてねということになっているので, コンパイラとかのバージョン管理は楽だと思います.
本音を言えばコンパイラもgithubで配布してくれればテストなどの継続保守が楽になるので検討して欲しいとこなのが1つ. GeForce(もっと欲を言えばJetson)のように安価に手元で試しやすいモデルを検討してほしいのが1つでしょうか. NECはAWSと協業するという話があるので,将来的にAWSなどから使えるようになると幸せなのですが.
githubで色々調べるとほとんどのソフトはErich Focht氏が書いているように見えます. まだまだユーザが少ないのは仕方ないですが,NEC社の人がpull requestしていたりするのが見えないので, OSSにするならもう少しオープンに開発したり出来ないのかなとか思いました(ポエム
そしてこのErich氏すごい.
私の頭の中では勝手にこの人をNECモスと呼んでいます(´・ω・`)
性能評価
ポエムに疲れてきたので,適当なコードを1つ使って簡単な性能評価をして終わろうと思います.
STREAMをやろうとおもいましたが,あえてC++で,かつ集約計算が必要な内積を書いてやってみました.
- 標準出力からの配列サイズの受け取り
- OpenMPとOpenMPのreduction
- std::vectorやstd::cout
など,ホストでは当然やりたいような要素を入れときました.
#include<omp.h>
#include<vector>
#include<iostream>
void main(int argc, char** argv){
size_t N = atoi(argv[1]);
std::vector<double> x(N, 1.0);
std::vector<double> y(N, 2.0);
double ans = 0;
double stime = omp_get_wtime();
#pragma omp parallel for reduction(+:ans)
for(int i = 0; i < N; i++){
ans += x[i] * y[i];
}
double time = omp_get_wtime() - stime;
std::cout << stime << "," << ans << std::endl;
}
それではコンパイルです.普通にVHにsshして VE用のバイナリと
nc++ -O3 -fopenmp -mvector test.cpp -o ve.out
VH用のバイナリを作ります
g++ 2.5.1 -O3 -fopenmp test.cpp -o vh.out
全く同じコードです. あとは出てきたバイナリを叩くだけです.
ちなみに -mvector をつけると自動ベクトル化がマッハで頑張りだすみたいな噂を聞きましたがつけてもつけなくても変わらんかったけどおまじないだと思ってつけてます.
では実行性能です.2N/time でプロットしてるのと,100回平均で時間はかってます.
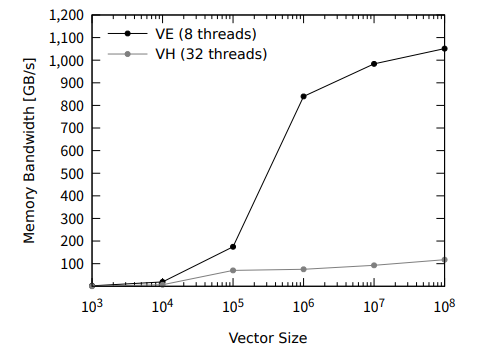
ちゃんとVEで1050 GB/sくらいまで帯域が引けて,VHの10倍くらいの性能が出ていることが分かります.
このときプロファイラによるベクトル化率は99%, 平均ベクトル長は255.7 (最大256)で,集約計算を含むような計算でもちゃんと自動ベクトル化されたことが分かります.
ちなみにCRS形式のSpMVのような間接参照が必要なケースでもちゃんと自動ベクトル化されました.[1]
ちなみにSTREAM系でも同じスコアが出ることを確認してます.
このように,何もしなくてもというのが,本当にほとんど何もしないでそこそこでたのは驚きでした. (Xeon Phiさんの「何もしない」に100回騙された)
その他の疎行列ベクトル積やFEM構造解析のFrontISTRの性能については 文献[1], 文献[2]にあるので興味があったら読んでみてください.
おわりに
本当にコンパイラを変えるだけでちゃんと動いてメモリを引ける,そんなSX-Aurora TSUBASAについて紹介してみました.
実際はマルチデバイスなんかをやろうとすると少し手間が入るんですが, 48GBというサイズに収まる範囲であればほとんど修正せずに動くというのは1つの完成された形な気がします.
GPUでもOpenACCやOpenMP Offloadingなどが使えますが,こちらはpragmaを入れずとも動いてくれるので, 簡単に動かしたいというニーズに対してはこちらのほうが叶えられているのではないでしょうか.
スレッドで稼がず,FMA演算器(3器)とベクトル(倍精度x32)というアプローチで計算性能を稼いでおり,単純な計算では流石はベクトル機といった性能でした.
このモデルを維持して何世代か続けられれば,x86_64やNVIDIAのGPUと戦ってくれる.戦ってほしいという感想です. 一方でOSSの開発プラットフォームははまだまだ発展途上という印象で,我々も含めて頑張らないといけないところです.
AWSなどに入ってくれればかなりCIなどでの継続テストもしやすくなるので,個人的にはそっちに期待です.
実際にSX-Auroraを使いたいという人はFOCUSスパコンにも導入されているので,そこから使うのが簡単かもしれません.
最後にCMですが,私は所属している科学計算総合研究所で FOCUSにおけるFrontISTRのサポートや, A64fx, SX-Aurora TSUBASA, GPUなどにおけるFrontISTRの高速化を担当しています.
通常ではCPUでしか動かないFrontISTRを高速なアクセラレータで動かしたいというご要望のある方は連絡いただけたら私ががんばります. また,FOCUSのリンクにある機械学習による設計フローの加速についても是非よろしくお願いします.